Tue 28 April 2026
Software Design Playbook
A PR should never be rejected for architectural decisions. When code is written the overall system should have already been planned and agreed upon.
There are two common types of software documents, the architectural decision record [ADR] and the software design document [SDD]. Companies can combine both or do with only an SDD. There's no one size fit all and not all software needs much thought.
Planning software is a recurring theme on my blog and this article attempts to provide the structure to how I plan and design.
ADRs
Architectural Decision Records are typically how decisions are expressed given the context and knowledge at the time. Martin Fowler will cover the topic of ADRs better than I.
SDDs
A Software Design Document is the specification detailing the system and the system's intent before it is built in order to encourage feedback and catch plot holes early in the development cycle of software.
Other than allowing us to get feedback before commitment they are a useful practice for the following reasons:
-
Discovering knowledge gaps. The practice of planning the system allows us to make an initial pass at realising an idea. The practice can bring to light areas we hadn't noticed and reveal that our logic doesn't make sense on paper.
-
Reflection. We learn over the course of a project and having a document that captures our assumptions at the start provides us with a meaningful document that we may reflect on and identify why we were initially wrong.
-
Prosperity. Systems are often forgotten, having a document that outlines the project's initial stated aims can provide an answer in the future when we ask "why did we do this?" Or someone new to the company asks "why did you build it like this?".
-
Getting buy in. It is tough to convince others of an idea in your head. As soon as it's on paper and there's clear logic to your conviction there will be more willingness of others to support. Projects that stand up well to criticism are also more likely to be convincing and picked up.
Template
These documents depend on the problem they aim to address and typically include the following sections:
Context
Tell the audience the problem you aim to solve and why it is important to solve it. Generally I define the state of the system at the current point in time and expose the gaps it has.
E.g. users are wanting double the portion of donuts, we only have 1 donut machine, if we buy another donut machine we will be able to serve twice as many donuts and multiply our profit by a factor of 2.
Scope
Make the limitations clear upfront. Tell the reader what the solution is not aiming to solve. The perfect software doesn't exist and if we tried to build it we would run out of time and runway. Setting boundaries allow us to focus on the core problem we aim to solve.
E.g. The donut machine will not address the users asking for apple juice.
Proposal
Start at a high level and break it down into its components in the subsequent sections. When communicating systems we must understand that individuals consume information differently, some are more visual than others. Knowing this we can enrich the document by providing more than a single representation of the point we are trying to make.
| Representation | Good For |
|---|---|
| Diagram | flows and relationships |
| List | overviews and sequences |
| Prose | nuance |
| Table | comparisons |
Even if a decision is minor the trade-offs should be tabulated. The choice can be obvious but the practice of assessing an alternative can reveal better solutions, and avoid falling into a Cargo Cult trap.1
Rejected Options
Avoid designing once, by including the rejected options we make this practice clear. Our first idea will not always be our best idea2. Understanding the weaknesses of our rejected options can also provide answers to the curious reader.
If we need to improve the system in the future; remembering why we rejected the other options may allow us to avoid them when we need to pivot. Unless something has changed, we might have a better understanding of options in the future and they'll become opportunities.
Optional Sections
These sections don't apply to all software designs, you might use all of them on a large document. Smaller changes to a system disregard them.
Cost
Money and time.
Provide cost and time estimates, these can give other departments a head start when considering pricing or capacity. Start with estimates or source price pages, something is better than nothing when it comes to informing the stakeholder of a go/no-go project.
Cost is not only found in raw compute. There's also the ongoing cost of upkeep; ensuring the system is up-to-date. Some systems require a member from support staff or an analyst for input on a regular basis, these are flagged as operational cost.
Risk
Address what can go wrong and cover how likely it is to happen. On large projects, some risks might not have a mitigation but we can address how to measure it and minimise it's impact by catching it as early as possible.
Determining the project's risk comes from experience. They range from technical risks like an overview of technical short cuts and their cons, to softer risks such as the introduction of friction affecting product adoption or the consequence of design affecting popular perception.
Goals
Every system should have a goals otherwise it's literally pointless, without a clear purpose the systems is debt before it gets off the ground. This also helps to alleviate scope creep as clearly defined goals allows us to cut any work that does not achieve the original stated purpose of the system.
Milestones
Through my experience I have found high level milestones can be useful, however if they are inflexible or significantly detailed they hold a project back.
The benefit of high level milestones is that it indicates a larger vision for the project and the potential long term impact it may have. We tend to learn over the course of the project so these should be flexible as we are bound to discover things up until the release of the first milestone that will impact our initial plan.
Getting feedback from the first users of your system can throw your roadmap and milestones in the bin.
Deep Dives
As a company scales the systems become more complex, complexity can also be introduced by regulation and some consideration needs to be made before bringing on 3rd party providers. To deal with this I have a shortlist to assess risks when designing software.
Certifications may be required if you are operating in specific industries such as healthcare. It's best to know upfront that you're integrating with a HIPAA compliant party than after the integration has completed. Finding out too late can be a huge waste of time.
Regionally locked data might be a requirement, GDPR, for example, requires explicit consent from an individual if their data is going to be transferred across regional boundaries. If you are integrating with a 3rd party you may need to confirm what regions they are able to operate in.
Authentication and permissions are commonly needed if we have to limit access to specific users or to subsets of users. Determining how permissions are granted and how users authenticate can impact the design of our systems.
Localisation is required by most medium size software businesses as they'll operate in more than a single language or more than a single currency. Serving multiple geographies require these considerations.
Security audits and assessments can be required before being able to use a provider's service. We should ensure the software we use is trustworthy if we are likely to send sensitive data.
These topics may be brought up under our section on risk, or during the discussion of trade-offs between solutions.
FAQ
There are questions that are asked more frequently than others, it's always helpful to include them. Even the off hand questions that were brought up in passing. Good questions can be more interesting than the answer.
Feedback
Feedback is often an opinion and can come from someone with lesser context but more experience. Figure out the quickest way to test an opinion. Don't get caught up on addressing everything but ensure you de-risk concerns by having a plan if their concern becomes a reality or making it easy to roll back or having circuit breakers or feature flags.
As an example a conversation around "this might not scale" could be countered with "this might not get a lot of traffic", systems don't need to be implemented with scale in mind, but they should have an answer that can address scaling if it becomes a concern unless you have some concrete evidence that it won't be a concern; such as; we don't think this will be used often by users but if it does we have a way to limit it's usage and have isolated it from the rest of the system so that if it starts getting attention it won't affect the performance of the whole system.
Do we always need an SDD?
One thing that has held true in software is that the earlier something is found in the process of developing software the easier it is to correct course. Software design documents are a way to map out the unknowns and identify blind spots in ideas. Not all ideas are complete, sometimes ideas come without a solution, we don't want to find ourselves a month into development to realise we don't know how the solution is actually meant to look.
Not all changes require deep thought or detailed specification. There should be room to explore and learn by hacking something together, but the exploration needs the bigger picture and the goal. Without purpose we are wasting time.
This article is longer than many of the design documents I've written.
Tue 21 April 2026
Probabilistic Data Structures
Keeping track of a constant set of items is fairly straight forward, however when the number of items start to grow larger than the capacity of a single machine things get expensive. There's a way around this and it's to rely on approximations instead of concrete numbers. There are two probabilistic data structures I'd like to cover in this post; Bloom Filters and Count-Min Sketch.
Generally these are applied when space is a constraint and you need predictable and consistent size. If you're counting or caching at scale there might be a chance that your database is relying on probability instead of certainty.
Hash Tables
A fundamental data structure in computer science is the hash table, useful in caching and counting, as well as representing objects in software.
A large hash table is often useful when you need a key value store such as one that would map user ID to a profile picture so that every request for a profile picture is speedy since hash tables operate in 0(1) for look ups.
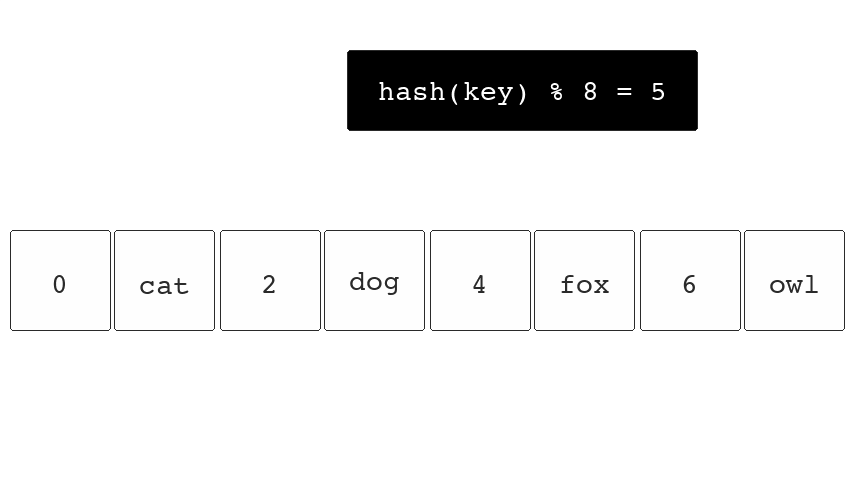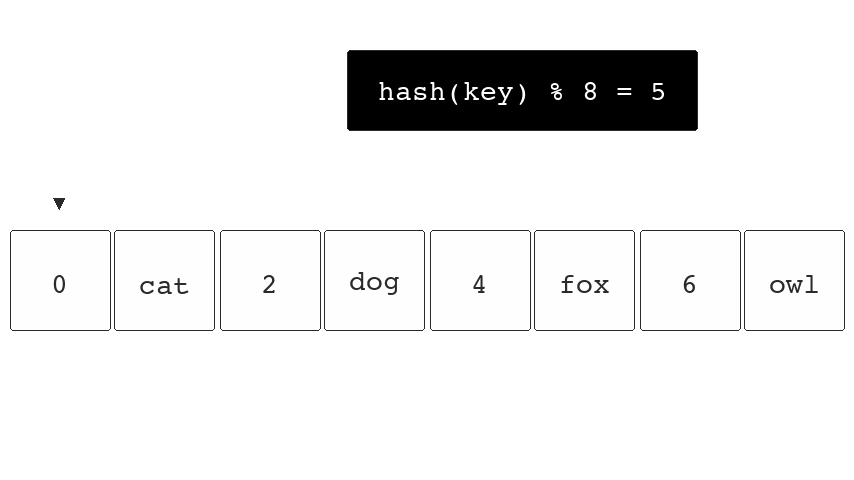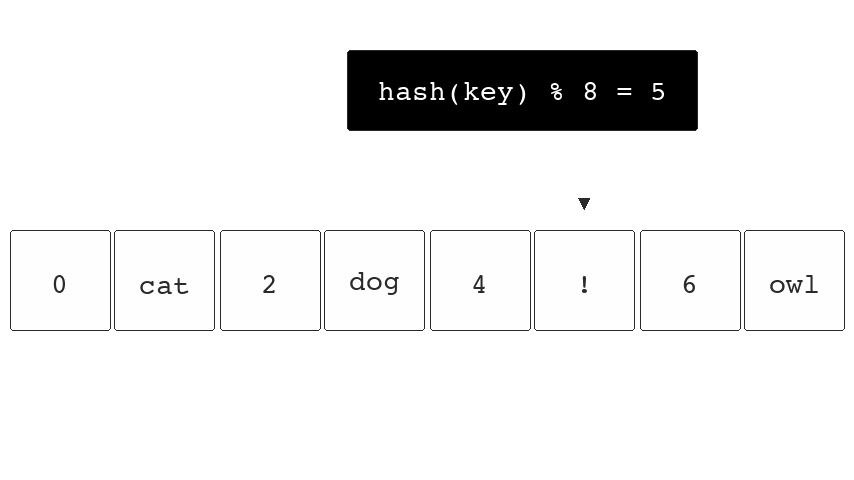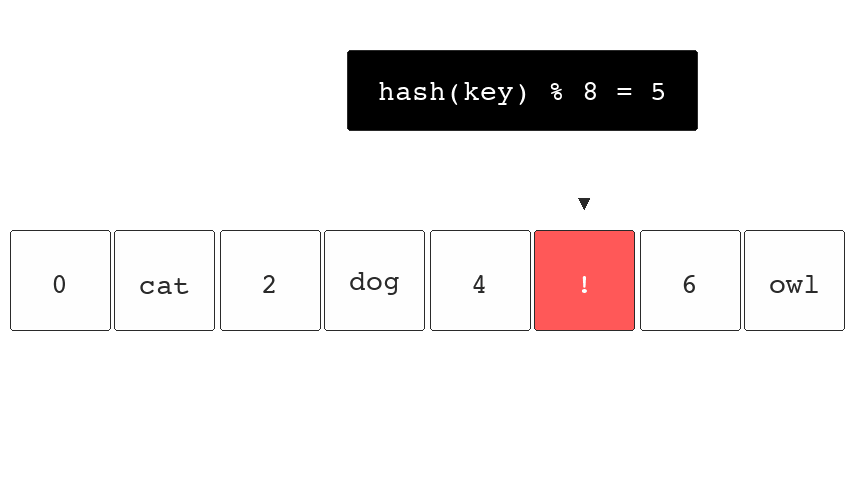
This is done by having a number of buckets and a function that consistently converts a key to the index of a bucket. This is called the hash function. A cache or a key value store only requires computing the hash to locate the data.
If we were to hash the key "fox" (hash("fox")) and the
resulting output was 5 we would know our data is in bucket
5.
Hash functions won't compute unique hashes and occasionally
they can collide with existing keys stored in the hash
table. So both hash("fox") and hash("cat") might end up
pointing to bucket 5. They can reduce the chance of this
happening by increasing the number of buckets. Having 10
keys and 1 million buckets means the chance of collision
becomes extremely small.
In practice hash tables store linked lists in the bucket locations and when a collision occurs they iterate through the list until it finds the key. When storing a new key it appends to the end of the list if it's not there already. Redis uses this technique in addition to resizing the number of buckets dynamically in-order-to keep the length of these lists to a minimum.
We can use hash tables to determine if we've seen something before, by storing keys as we see them, if the key exists in the hash table we know that this isn't the first time we've seen the item.
Bloom Filters
When we start dealing with data streams or billions of users, storing everything in memory can be expensive. Instead we can reduce the total memory consumed by using a probabilistic data structure; the bloom filter.
Bloom filters rely on approximate set inclusion. So instead of yes this item is in the set or no it isn't; we get the following outcome:
- This item is not in the set.
- This item might be in the set.
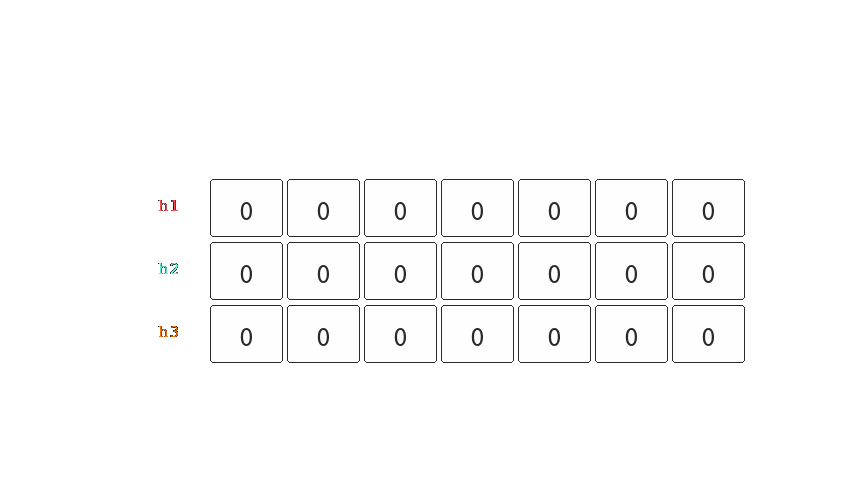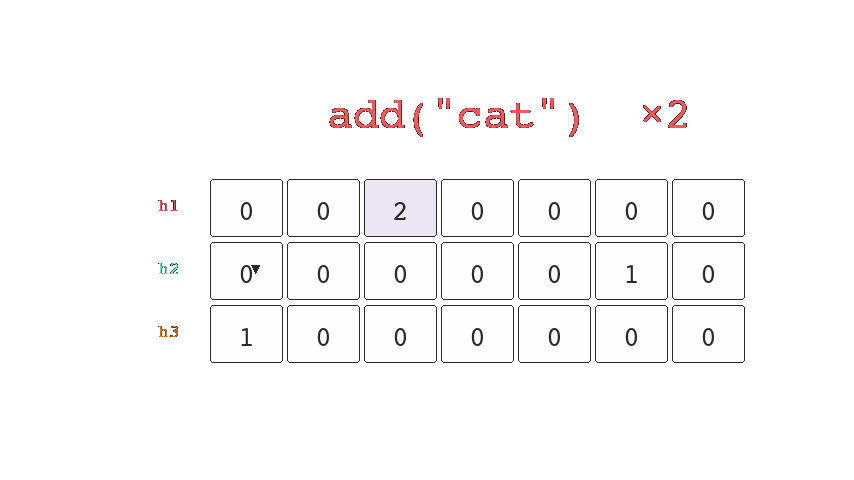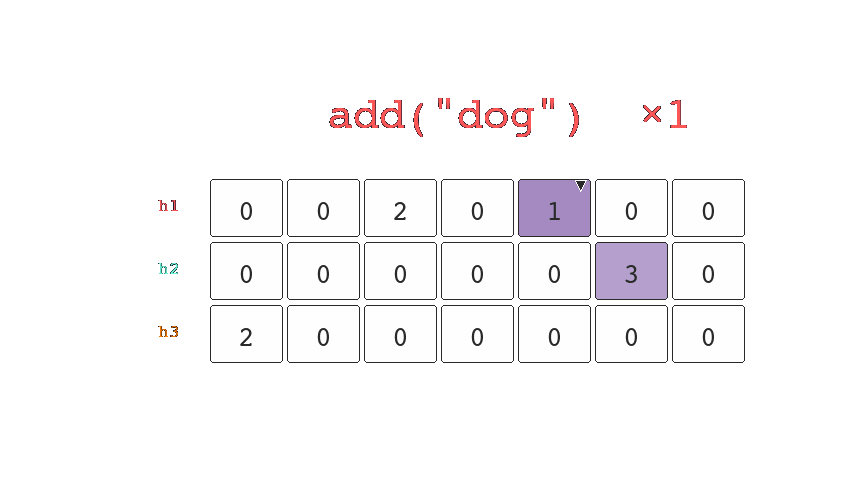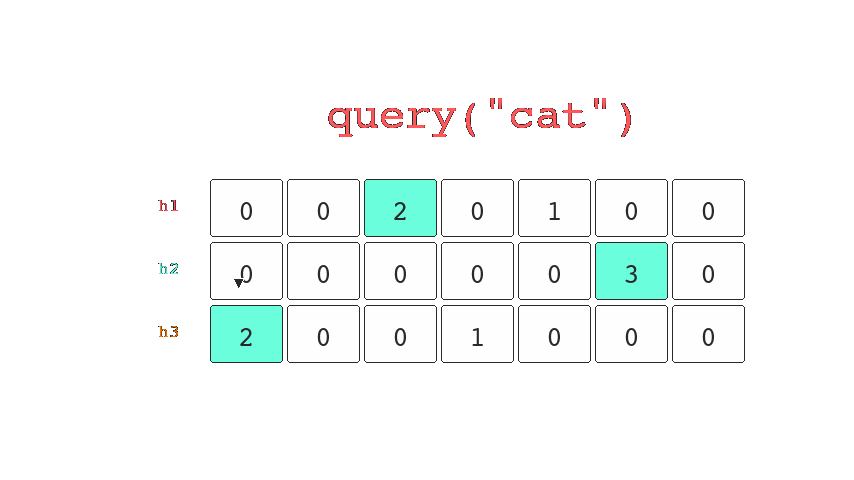
This is done by having a consistent number of buckets and using more than one hash function. As you can see in the illustration below, the key is hashed three times and each resultant bucket is set to 1.

When items are queried we will know for sure that we haven't seen it before if any of the buckets return a 0. However if all the buckets result in a collision then we know that we might have seen it before.
Both the number of buckets and hashes can be configured which allows us to trade more space for a reduction in the probability that we return false negatives. (We might have seen it, when we haven't).
The bloom filter is applied in situations where space is limited and keeping track of every element isn't an option. If we wish to avoid making expensive queries for data that doesn't exist; a bloom filter can help us reduce the number of expensive queries.
Browsers have used bloom filters in the past by providing a preset filter of malicious URLs. When we visit a URL and it's not included in the filter we can proceed however if it might be in the filter we can query a server to help determine if it's safe or not. We avoid this query on the majority of URLs as most URLs are safe.
Count-Min Sketch
The last probabilistic data structure I'd like to cover is the Count-Min Sketch, like a bloom filter it has multiple hash functions, unlike the bloom filter it tracks the number of times a key lands in a bucket.
When queried it hashes the key and returns the minimum from the counts stored in the corresponding buckets. This allows us to determine an upper bound estimate for the number of times we've seen a key.
Count-Min Sketch is useful in large scale data processing,
for example if we are interested in tracking the top-k
searches we can do this normally by using a heap. If we have
size restrictions and need to use constant space instead of
O(n) space we can put the sketch in front of the heap.
Heap inserts are done in log(n) time which we can avoid
doing if we know the item shouldn't be in the heap. Items
that appear infrequently are then discarded before even
making it to the heap. We do this by querying the sketch for
an upper bound of the new item, for example 3, and if the kth
item in our heap has 12 appearances then we can avoid adding
the new item to the heap.
I have found it interesting that at scale we can use probability to optimise our systems but it also requires an understanding of how the data is distributed. These data structures work well on long tail distributions but when all items are as frequent as each other these become less useful. It would be interesting to discover how systems can map to different distributions of data and how these structures are set up to solve the given problems.
Mon 13 April 2026
Setting up success
I have a frightening memory of joining a company and my
first Pull Request required me to SSH into a
compute instance and do a git pull in order to release my
change into production. On that occasion I found that I
was also deploying more than just my change as the branch
was not entirely up to date.
There's a battle of trade-offs in software where things that sound good on paper are often placed in the backlog and forgotten about. Something about the process being good enough or being the way things have always been done that kicks valid improvements down the priority list. It is with luck that some are granted the privileged to determine what they get to work on and companies will give that chance to people that have agency and a strong conviction that they know better.
How it began
The other pattern I noticed at that company was a lack of dev and prod environments. Everyone with access to the project had access to everything. At this stage the company was on-boarding more engineers and data scientists and each of them were being granted full access to this monolithic environment.
It was even more exciting to find legacy projects without owners and services being deployed into production using the developer's container orchestrator of choice. Docker-compose, Mesos, self-hosted kubernetes or GKS.
The company was growing quickly and it felt like with every new developer there was a new way to release changes into production. Every fire I was pulled into appeared to be running on it's own tech stack and required learning how things operated from the ground up. Nothing seemed transferable from one project to the next.
These were the problems I had determined to solve.
Taking on the problem
Over a week I mustered together a team to tackle this complexity. The first thing was a meeting with the CTO to propose setting up two new project environments; one for dev and one for prod. This was an easy request as the CTO was horrified to learn that things were being deployed straight to production.
The next thing to setup was a CI/CD pipeline that is generic enough to be used across any service. This meant that if you wanted to use our new dev/prod environments your servers had to be deployed through our automated pipelines. To help the other teams we wrote a service template and helm chart that would play nice with CI/CD. This also meant that we restricted the deployments to a single hosted container orchestrator and allowed us to consolidate all the different styles of deployment. As a consequence we were able to help across more teams as they ran into issues due to us becoming more familiar with kubernetes and not having to understand an entirely new workflow or orchestrator.
The Fun Didn't Stop
We had an outage at around 2pm in the afternoon when the company lost connection to all the servers in the production environment. At this point we had around 5 teams deploying code on our stack. An urgent message in one of the slack channel asking if anyone had changed something revealed that someone had assigned their service a new IP range which masked our network bridge to the rest of the company.
This is when we introduced terraform. Any network changes or changes to the infrastructure could now be reviewed, reverted and audited since it was defined in code. If something went wrong we could investigate the changes as well as having our infra committed to version control. We saw the introduction of terraform improve the adoption of our stack as new engineers were frightened to work in the other cow-boy projects that had existed on infra configured by hand through the web UI.
We started to notice that other teams were adopting our tech stack as they no longer needed to spend time on defining the release process as we had a template that they could clone and get started almost immediately. Now they could tackle business problems instead of weighing up the trade-offs of each container orchestrator.
Our helm chart also helped, we got rid of the mountains of bespoke yaml used for several k8s deployments. We could also serve engineers with features such as specifying cron jobs with very little configuration in their service spec. Most teams were data intensive and relied on scheduled batch processes, so in some cases they had only adopted these cronjobs.
We also developed a library for new services that setup logging, sentry integration, trace IDs and database connections and introduced a standard for running database migrations in the service template. At this point is was quite important to encourage shared ownership of these codebases. The more open we were to changes from other teams the more likely they were to use it and benefit other teams from these changes. This broke down the silos that had existed previously, as improvements were no longer isolated to a single service but could now be utilised across the company. It also meant these libraries were improving without needing someone on my team working on it full-time.
Clear Sailing
My team of 5 was serving 80 engineers and data scientists across 12 teams. Upon reflection not everything went smoothly. There were people that wanted to maintain control over their entire stack, perhaps we were a bit stretched and couldn't focus on features they required at the time. They might have also had disagreements with choices we had made in the service template.
There were also features we developed that didn't get adopted, which makes sense to me now. These were things that generally slowed people down for very little benefit. Contract testing is an example of this. On paper having clear contracts between services and having a means to define and test these contracts sounds like a great idea. The nature of the services at the time, being cronjobs or at most two endpoints meant that their interfaces weren't growing in complexity and introducing this step in the build process wasn't a big enough bang for their buck.
Service to service authentication was another feature that we didn't need at that time. Our services were internal and in a VPC. Obviously if we were compromised not being able to send requests to the servers in that network would be a great thing to have, but I think it would have been better to sink time into features that would speed up the adoption of our workflow instead of features that added friction. Not to say we didn't need this auth layer but we could have potentially address this at a later point.
Improvements
There are improvements to the workflows that I would have enjoyed introducing. For example; using a CI/CD server that didn't rely on defining our workflows in Kotlin. I feel that Kotlin added a barrier to contributions and we didn't need this. There are other CI/CD tools like gocd.org and concourse-ci.org which have an easier way of defining workflows. Although now-a-days we can get a lot done with github workflows and reduce the reliance on having a CI server.
We attempted introducing Istio, however, at the time this was an aspirational feature but if we had succeeded we would have allowed our teams to run canary deployments, which would allow them to divert a small amount of traffic to a new version of their service and if anything goes wrong, it avoids rolling out the broken version to all customers.
I still seem to come across companies that only give leadership the ability to deploy to production and changes go out once mid week. When this is the practice many changes tend to accumulate and when they're released everything goes out as a big-bang deployment. When something breaks in these scenarios it's often harder to pinpoint what went wrong. Smaller frequent deployments grants autonomy and shortens the feedback loop which speeds up a developer finding out what went wrong, releases also tend to be less disruptive and engineer's have a higher confidence in the changes they release into the world.
The biggest take away from my experience in leading an infra team is that we learn by making mistakes, so we shouldn't try reduce the number of mistakes we make. We must focus on reducing the cost of the mistake through incremental change, rollbacks and observability. Many companies and teams try to make no mistake at all and in doing so they cost themselves growth.
Mon 16 March 2026
Learning from Sales
It is not the job of sales to find customers with problems that we have solved, but also to find the problems that we can potentially solve. The role is one part customer relations and one part business development.
The challenge with this role is that features fall on a spectrum from nice-to-have to critical-for-business; being able to tell the difference is a key skill for anyone in sales. If we filter all the nice-to-have functionality out of the developer's backlog what remains is the high value and impactful functions that allow us to sign more deals.
Engineering teams often miss this business context and lack the skill to differentiate these features. Part of the problem stems from being a few steps removed from the customer and nice-to-have features can appear more exciting to work on but don't end up creating value.
Engineers that wish to be highly autonomous and are charged with seeking impactful work need to exercise their inner salesperson. Those that don't embrace these skills are at risk of wasting their time and working on the wrong thing.
Buy Signals
Those in sales and business dev look for hints that inform them of the project's potential to get to the deal signing stage. Focusing on projects with high potential allows us to avoid chasing cases that won't move forward or are likely to end without being closed.
If more than one customer is asking for a feature this can be an obvious indication that focusing on this can provide more impact. If you're working on internal software infrastructure, are you getting a feature request from more than one team, or is it from the esoteric data scientist that seems to have their own bespoke setup?
Sales rely on buy signals. A buy signal can indicate when a client is excited enough by a solution that they are willing to consider a purchase. The most obvious way they signal this is by giving you money. If they're trying to give you money before the solution is built, you'll know the solution is somewhat important to them.
We don't have to rely on the client putting down money for us to recognise a buy signal. Buy signals can appear from any skin a customer is willing to risk for a solution. If a customer is willing to vouch for the product to a superior this is a political stake. This allows us to move up the decision chain and provides a positive signal that a deal can make it to close. We also use this as a way of making progress in conversations without explicitly asking for money.
Software engineers should want to get closer to the projects that have the largest impact. We can use buy signals to determine the projects with the most buy-in from leadership and create the most business.
Discovery Questions
Developers can find themselves working on the right project but can end up developing the wrong thing without an accurate idea of the pain-point. We need to peel back the layers that surround a customer's pain to determine how we may best deliver.
Sales do this with discovery sessions or hearing it directly from the customer. Their goal is to avoid making incorrect assumptions about the problem which may lead to building the wrong solution. Software engineers could also benefit from this skill. If you're given a spec an engineer should ensure they're delivering the appropriate fix, otherwise they risk missing the target and have to do revisions or start again from scratch.
Sales does this with open ended questions, the more space they provide a customer to explore the problem the higher the chance we expose insight. Getting them to dig deeper on specific points can expose issues they might be having and asking how a solution might affect their business can help sales qualify this lead.
A classic technique of getting your customer to talk is called Mirroring covered in "Never Split the Difference" by Chris Voss.
Are your developers asking enough questions to expose misaligned assumptions?
Touch Points
Progress updates with customers allow you to show that you are keeping them in mind and their requests haven't been forgotten about. They also provide a heads up when new features are near release. They are used to build trust and allow the customer to feel like they are helping guide the process.
If your wins are also their wins they will feel like they have more skin in the project's success and become an internal champion across the industry and in their own business.
How often do you provide a task to a developer and only hear about it three months later when there's just two weeks until the deadline?
Regular touch points don't just serve the relationship you are building with your customers but also allow you to validate the project closer to real-time. Ensuring that you are headed in the correct direction is critical for success. If you're heading down the wrong path you'll want to know as soon as possible.
It's a shame that developers seem to be stereotyped as introverts lacking people skills that wish to be isolated from any call with the customer. The industry appears to lean into this idea by adding more barriers between the client and developer. The truth is the companies that have their developers closest to users and customers are the ones that succeed and the best way for an engineer to level up is to care more about the customer.
Determine Timelines
Software can rely on external processes and teams. Figure out what you're building and predict where you might need approvals or contracts, this will allow you to get the ball rolling in those departments. Sales already do this on their discovery calls by probing if the customer will need to bump other departments, bumping them now can lead to less delay.
Within a company we might require a third party tool for the new feature we're developing, so the sooner we loop in finance or the security team the better. We can have them work on their specifics in the background while we work on the feature. We can probe our PM before we start the project that we might require looping in these other teams.
We should also determine when something will be needed and understand the timeline. They could be aiming to deploy their MVP in a month which could affect how we prioritise building the solution. If the deadline is tight, perhaps we can determine if there's only a subset of features required for the MVP and avoid sinking time into the features that are expected at a later time.
Alignment
Developers can level themselves up by becoming more aligned with the business and not less. One way of doing this is by moving closer to the customer or learning how other roles operate. Software will continue to be a competitive industry and engineers can't afford to waste time on things that don't delight their users and/or provide impact.
Mon 09 March 2026
The Moderate Take
Economics and politics are determined by the most compelling stories and occasionally it is hit by reality. This is one of the challenges when following reactionary discourses on platforms like Linkedin, Reddit and Twitter.
When advice comes from board members and VCs I am reminded that they scroll the same threads on reddit that I do. Their opinion is often shaped by the highest voted comment in these forums.
Unfortunately we aren't gripped by stories that are filled with the context and the caveats that exist in the real world and this has shifted us into more extreme political leanings. Why should we fill our content with details when this jeopardizes the opportunity of going viral.

False narratives get the clicks and impact stocks because they're entertaining and persuading. We are willing to sit still and listen to the stories that are novel and gripping. 14 years ago Elon said we would land people on Mars in 10 years. (15-20 years in the worst-case).
including caveats all the time makes articles too awkward to read and buries your actual point
No one finds being moderate sexy.
The boring parts of software
The engineers that have the largest impact are the ones that read the most documentation. Getting through software specs is tough, they're not filled with fluffy prose and they're often dense and technical, but nothing delivers value like saying: "We don't need to do that work, that feature already exists in the API".
Similarly, the largest mistakes I've seen made in software come from conclusions being made too quickly after reading a single page of documentation. Engineers also avoid reading documentation by jumping on a band wagon of agreement without verification.
This extends to how reactionary takes tend to mold their opinions. Life is easier when someone does the work for you. If things go belly up, hey that wasn't my misinterpretation.
Where's it shifting?
This doesn't just apply to engineer's, Steve Eisman had this to say about the finance industry in 2008, but this applies to everyone.
I think one of the hardest things for all human beings, me too, to deal with our paradigm shifts. You know, you exist in a paradigm. It's been around from a very, very long time. Your whole career is based on that paradigm. you've made a lot of money in that paradigm and then it turns out that the paradigm is either changing because of technology or maybe the paradigm was actually wrong because it was based on continuously increasing leverage which is what the financial services industry's paradigm was based on human beings have tremendously difficult time dealing with paradigm shifts. Tremendous.
It's like a nightmare. They don't want to deal with it.
- Steve Eisman A.k.a Steve Carell in The Big Short
r/ExperiencedDevs is an echo chamber degrading Ai slop and crafting existential dread in the industry. They assert that Ai can never be as detailed or accurate as they are when it comes to writing code, at the same time they're shaking in their boots about the future of their industry. When there's commentary on the benefits of AI these comments tend to be downvoted or deleted and the blame is put on automated bots making up pro-ai agitprop.
Software engineers tend to be defensive when it comes to generative code and state that most of their job wasn't code to begin with.1 These engineers aren't out of the "Ai makes mistakes" phase or they're moving goal post to take the target off their back.
The latest cohort of uni students are winning hack-a-thons without knowing how their applications works. r/ExperiencedDevs needs to come to terms with the unknown and as long as this industry has been around we've never actually known how projects work in their entirety. We've never read every line of code in our dependencies, not knowing how something works and being able to make contributions is not a new phenomenon. Those that have succeeded in this industry can wade through the unknown and that will continue to be the case.
It's normal to have strong feelings about the grads picking something up in a short amount of time that may have taken you longer to hone in on. It's the classic "back in my day" reaction.
Extremes
Unfortunately avoiding nuance leads us to extremes.
The truth is; software engineering looks different and requires different skills at different stages of the business and stack. These complaints might just be a misalignment with the business.
Ousterhout describes in his book "A Philosophy of Software Design" the difference between strategic coding and tactical coding. Where tactical coding relies on hacks to get the job done and strategic coding has a more long term view on the code base. He vouches that software should be done strategically but I believe we need to pick our battles.
There are some entities and functions that are core to engineering companies, but they become core at different times and we should make an attempt to recognise when this change occurs.
It is nice to pretend that your code is an integral part to the business's existence. The truth is a project is always initially an experiment and over time it is rewritten to more accurate specification as we learn and the business learns. Importance is discovered. Your first attempt will be done when you know the least about the topic.
Eventually it might become a core service to many teams within the company and at that point it's worth getting serious about engineering practices. Front loading your engineering standards is making your experimentation more expensive.
If you're treating every project like a personal flower garden you'll struggle to recognise when code is dead weight. Thank it for its cycles, praise it for the outage it caused, the war story and what you have learnt. Then delete it.
Software is about discovery. Code generation enables us to prototype and discover how things work. Prototype for your own education not just for the customer. The pace of learning has increased and we can discover and experiment quicker than ever.
-
Like I did in "Software is planning" ↩