Mon 02 March 2026
Get more out of 1:1s
There isn't a course or career training when it comes to the one to ones with a line-manager. Every manager conducts them in their own way, and what happens in them can sometimes feel secretive. So here's a look under the curtain on how to get more from these meetings.
When you realise that your manager is human these meetings become easier. Once you start giving more accurate descriptions on where you'd like to grow, what you want to work on and share what you've achieved the meeting becomes more productive.
Unfortunately these meetings rely on how well you know yourself. Since managers don't possess an innate ability to know what makes you happy or what your goals and aspirations are. Opening up can feel like a sign of weakness or make you feel more vulnerable, but the more you share the easier you make it for them to help you achieve your goals.
So what does a good one to one look like?1
You set the agenda
We should approach setting the agenda pragmatically, if you are short on time come up with a few question that will lead to a productive outcome that you can ask in every catchup. The one question I typically ask is: How does the rest of the team feel?
This allows me to determine how confident others might be about a project. It helps me become aware of colleagues that are feeling stretched and could use my help or perhaps they wish me to help out in different ways. I've found this to be an effective way to find the gaps that need filling.
The areas you should be creating questions around should be on your general feeling about work, work-life balance, your growth, your interactions with others on your team and company and the progress you've made on tasks and goals. You don't need to fit this all into one catch up but theming your next catch up on one of these topics can help you prepare and get you started.
Achievements should be brought up. This is emphasised in a remote company, where your achievements can be missed if you're telling no one about them. A good manager will pass your achievements around the office, because typically their performance is tied to your own and you're trying to achieve as a team.
Sharing achievements builds trust, once those big ticket items land on the team's plate and they need someone to lead it. The rapport you've built up with your manager might just land you these challenges.
Coach your manager
If you layout sensitive scenarios for your manager this can help you broach a topic or help you handle those situations if you are ever in that position. It can also establish expectations and intent. As an example you could ask how they would let you know if you were underperforming or what an early sign might be.
Your manager is a sounding board. If you have someone in your team that isn't meeting expectations asking them for help is ok, but be sure to prepare how you'll handle the situation so it doesn't look like you're trying to avoid responsibility.
Align yourself with your manager's priorities. This can help you be more aligned with the business objectives and become more valuable to your manager. If you help them they'll probably want you to stick around and if their scope increases so might yours.
Give your managers work to do. If you find yourself working on something that is not challenging or can be tedious try giving it to your manager. If you pitch them something more important that you could be delivering they'll take the tedious blockers away from you.2
Sharpen your ideas
Only call the vote once you know you're going to win
There's an overhead to collaboration, and if you had to listen to every idea in the business you wouldn't have time to do any work. Use your manager to sharpen your ideas, convince them before convincing anyone else. If you slowly get people onto your side through catch ups when you present the idea to the business you'll already know how to answer the probing questions.
Use the time to develop your relationship and your ideas. Your manager has insight into who is working on what and they can direct you to the people that are excited to talk to you about your ideas and these people might know the challenges you are heading into.
Know Yourself
The classic "where do you want to be in 5 years" question isn't asked to determine if you will have a future at the company. The question is used to determine how well you know yourself. If you are managing someone that is unsure about what they enjoy or what makes them happy how are you going to put them on the work they are most passionate about.
It takes work to understand yourself so mentioning this to your manager can allow them to throw all sorts of tasks at you to see what you're best at. They can help you identify your weaknesses and strength. However they'll not do this unless you're comfortable with the challenge and the way to signal that you're comfortable is to ask.
Your manager will also provide you with work you enjoy and having a history of catch ups in which you've said "I really enjoyed working on x" can increase the chance you will work on those things.
Use your manager to polish your strengths and strengthen your weaknesses. Much of this comes with knowing yourself.
Discuss your weaknesses
The best way to deal with a weakness is by opening up to your manager. Then you can work to find situations that will allow you to improve and make mistakes. Don't expect them to provide you a magical solution to your weakness, some weaknesses take time to develop into a strength and skills take practice.
They can provide you some structure and ideas for actions but they can also provide you with work that allows you to stretch yourself. The best way to learn is to make note of mistakes so getting the opportunity to make more of them is worth while.
Not just your manager
When you're in a company you have access to people with all sorts of skills. People that know stuff that you don't, and you can utilise this for your own growth and understanding.
Try catch up with someone in sales and ask questions like, "What about sales would you like more software engineers to know?"
Or set one up with someone in product and ask how they ensure we are working on the best thing?
Finally
To summarise a lot of these meetings depend on what you want to get out of them and this article touches on some of the topics you might wish to dive into during these catch ups. Although they might be biased towards what I try to get out of them.
Perhaps managers could ask you to set up questions for the next meeting but they probably wish to avoid putting any unnecessary pressure on you as there can be personal reasons why someone doesn't wish to gun for more responsibility at this time.
The key is having more empathy with your manager, they probably have their own goals so use them as an example.
Mon 23 February 2026
Review: A Philosophy of Software Design
Last year I read the book 'A Philosophy of Software Design' by Ousterhout. After finishing the book I wrote a review and reading it back I thought I should follow up with a reflection, the reflection is not yet written this is just the review.
The Review
The book offers an alternative perspective on existing approaches to software design in ways that are more pragmatic, with a strong focus on the core principle in software engineering; to tackle complexity.
Ousterhout clearly understands the power of abstraction as a tool for managing complexity and he applies this himself by creating his own metaphor for how software should be designed. He describes systems as having interfaces that should be shallow and implementations that should be deep. A simpler interface will provide less cognitive load than one with a larger surface area and if the implementation is deep it will provide significant power to the user.
Interestingly he also attempts to avoid jargon while describing things such as preferring to say "avoid duplication" instead of spelling out DRY. I believe he does this to allow the reader to grapple about how they are designing software instead of falling back on a adages like DRY as a core tenet without applying thought into what one is actually aiming to achieve. In other words I believe he wants the reader to make intentional choices when it comes to designing software.
Some of the example he uses are obvious to those that have experience reading code, most notably his sections on code comments, however I think his assertion that people don't write documentation upfront because they view is as "drudge work" is true.
He only starts mentioning cognitive leverage in concluding chapters of the book, I think it should be quite a core principle but perhaps a foundation is needed first to then understand how one can use leverage.
A lot of the book I agree with but I'd perhaps want to provide an alternative view on some of the areas he mentions.
The book makes a strong argument that we need to think more about software design than we are doing, I think there's also a balance to be made here. A good developer should be able to figure out if software should be done tactically or if it should be done strategically. Tactical coding does lead us to worst code in the long term and I've seen tactical more often than not, however I don't believe we should constantly be under strategic programming but as an industry and for early career developers we need more of it. Some software doesn't need design but that's an edge case and shouldn't ever be used as an excuse to avoid thinking through a problem.
In my view where developers lack the most thought and tend to create shallowest interfaces are when creating modules.
Shallow modules are a plague in the industry, I've seen very few examples where a developer has realised that modules are themselves an abstraction and a module's design should be considered. Too often we look at the method signature or class methods and believe this is where we create interfaces and abstraction. We must not forget the file or package is itself an abstraction and we should be thinking intentionally about its interface.
I enjoyed his emphasis on thinking "about different pieces of knowledge that are needed to carry out the tasks of your application". Finding the correct balance is a developer skill that can only improve when you consider and make intentional decisions about how you lay out your code, often avoided (and now offloaded) by engineers as it requires us to put in more effort with thinking.
One of the most important elements of software design is determining who needs to know what, and when
Page 43.
When solving a problem, it is far easier to rationalise and decide on your best course of action when that problem can fit in a paragraph. Isolating the relevant information in one space helps, having to go back and forth between pages or modules is a clear indication that the design has a flaw and my impression is that Ousterhout would agree with this. Further to this point, I believe an IDE can make finding all relevant parts of the code easier but doesn't address the core issue, and over reliance on the IDE will suppress issues and complexity creep.
TDD
I don't agree with his take on test-driven-development, in some cases it forces the developer to start thinking about the interface as a user. Writing the test gets you thinking about the module as a user of the module, since a simple interface would hopefully lead to simpler tests. Some of the key design flaws in an original design or even after the design has been done comes from actually using the module.
Leaving comments
I have come to realise that we have access to many tools that can be used in software design and focusing on using them to address complexity should be their main concern. Many of the examples with comments are in their usage, because we have access to comments doesn't mean we should use them for everything and we should be open to discovering more creative ways to leverage comments to tackle complexity.
Reading the code of others helps us discover interesting ways these tools may be utilised and helps us improve in these areas of software engineering.
One of the key points he makes is about determining the obviousness of the software which connects with how I've approached writing code and how I believe the design of software should be faced.
Perfection is achieved, not when there is nothing more to add, but when there is nothing left to take away.
Antoine de Saint-Exupéry
Mon 19 January 2026
Chess Programming - Moving
The "Chess Programming" series:
-
2: (here) Chess Programming - Moving
Attempts to create an automatic chess calculator date back to 1913. Chess engine software has had many optimisations and many minds involved in its evolution.
Last year I wrote on how chess programs track the position of every piece. This article is a slice of the chess engine research I compiled when constructing my own chess AI and covers how a chess engine resolves where a piece can move on the board.
You canplay against that chess engine here.
Bit Operations
So far we've covered how to use a 64 bit integer to track the positions of each piece and we've covered how to use bit operations to determine their type and colour.
Now the goal is to compute a 64 bit int that represents the potential positions that a piece can either move-to or attack. This number is called the "moveboard".
If we have a moveboard for a particular piece we can & the
positions of the opposing pieces in order to get attacking
positions and we can subtract the positions of all pieces in
order to avoid moving a piece to an occupied position.
If we simplify this to a single position on the board.
Given that we are able to move to this position, i.e. the
moveboard is 1, and if we consider it occupied by the
opposition, i.e. having a variable called "theirs"
being 1.
Computing the attacks is determined by doing the following:
>>> moveboard & theirs
1
This tells us the position is a valid attack. If the
opposition does not occupy that position (theirs == 0).
Computing for attacks would result in 0. There's nothing
to attack.
To compute valid moves, if theirs is 0 and ours is 1, we
do the following:
>>> moveboard & ~(theirs | ours)
0
This indicates that we can't move to this position. If the result was 1 then it would be empty and it would be a valid position for our piece to move. If we use 64 bit integer instead of a single bit, as shown in the example, the processor can determine the valid moves and attacks across the entire board in a single operation.1
Pawns
There's an edge case with pawns however, they do not use a
moveboard to determine the valid moves and attacks as
the positions a pawn may attack are different to where it
may move. Despite this they are still relatively simple.
Given a pawn in the middle of the board we only need to shift it up to determine its set of moves and after subtracting occupied positions we can determine if the pawn can move ahead or not.
# Shifting up
pawn_position >> 8

To determine if that pawn can attack we shift the pawn twice, "up and left" as well as "up and right". We then check to see if the opposition occupies these positions, this will determine valid attacks for the pawn.
# Shifting "up & left" as well as "up & right"
pawn_position >> 7 && pawn_position >> 9

Knights
Things get more interesting when we compute valid moves and attacks for a knight, but how does a knight move?
The knight is interesting because it's the only piece that is unrestricted by the position of other pieces. I.e. it can jump over pieces to get to where it wants to go. A knight in the centre of the board can move to the following locations:

If we had a
knight sitting on the ith index represented by the "bitboard"
variable we can compute the moveboard for the knight by doing the
following shifts:
(
((bitboard & NOT_H_FILE) >> 15)
| ((bitboard & NOT_A_FILE) >> 17)
| ((bitboard & NOT_GH_FILE) >> 6)
| ((bitboard & NOT_AB_FILE) >> 10)
| ((bitboard & NOT_H_FILE) << 17)
| ((bitboard & NOT_A_FILE) << 15)
| ((bitboard & NOT_GH_FILE) << 10)
| ((bitboard & NOT_AB_FILE) << 6)
)
There are four knights on a chess board, so this calculation would need to be done 4 times for every new board state. Since the performance of a chess engine is largely determined by how far into the future it can look, reducing the number of calculations on each board state can enable the engine to perform a deeper search.
To avoid these computations, we can simply pre-compute the moveboard for every square on the chess board before the game begins. We can then provide the engine with a lookup table, mapping all positions to their moveboard. Avoiding the overhead of computing them during the game.
Sliding
We also do this for the sliding pieces on a chess board. The rooks, bishops and queens move in a way that are considered as sliding.
Again we pre-compute all these positions and store the result in a map, however this isn't the final moveboard for sliding pieces.

Pieces closer to a sliding piece block its path and unlike the knight sliding pieces can't jump over these obstructions. So the resulting bitmask can't be used to determine the valid moves and attacks on its own.
The bitmask is used to identify the potential blockers along a sliding piece's direction of movement. Indicated in orange below:

Once we have identified the potential blockers we use this value to map to the final moveboard. This allows us to look up any moveboard using all combinations of potential blockers during the game and avoids having to shift the piece's position along its sliding axis for every new board state.

As explained we can use a moveboard to compute the
attacking positions (moveboard & theirs). As well as the
valid positions for moving (moveboard & ~(theirs|ours)).
In summary the following steps are needed to find the attacking positions and moving positions for a rook:
- Given the rook's position lookup the bitmask of an
unobstructed rook.
(index -> bitmask) - Use the unobstructed bitmask to find potential
blockers given all the pieces on the board.
(bitmask & (theirs|ours)) - Using the locations of all the blockers lookup the final
moveboard for the rook.
(blockers -> moveboard).
Computing potential blockers can be simplified as there are positions on the board that would never block a sliding piece. Such as positions on the edge of the board.
Given a rook in any of the positions indicated in red we can ignore positions in black as having "potential blockers".

This reduces the overall number of potential blocker combinations we need to consider, improving the engine's start-up time and memory footprint.
We do the same for bishops, except these potential blockers are computed diagonally and finally we compute the moveboard for the queens by combining the outcomes of the rook and the bishop.
Playing Chess
Now that we are able to compute the set of possible moves and attacks for each piece on the chessboard. Picking a piece at random and picking one of the positions from it's set of move and set of attacks will allow a computer to play against us.
This chess engine would still make illegal moves. To play a legal game of chess we would need to consider if the king is in check or if moving a piece might result in your own king being in check.
Finally; in-order-to implement all legal chess moves we would need to extend our move sets to include pushing the pawn twice when it is on its starting position, en passant and the ability to castle your king.
It might be more interesting, however, to dive into how a chess engine evaluates the board state so that it can make an informed decision when it moves a chess piece.
-
Assuming you have a 64 bit processor. ↩
Mon 12 January 2026
Seating Charts
We have two large tables and 100 guests coming to our wedding and we have to figure out how they will be seated. Defining the seating chart tends to be the most enjoyable part of wedding planning1.
After drawing circles for all the seats and guests in excalidraw.com, I began connecting the circles with colourful lines to map out specific relationships. As an example, a couple at the wedding should be seated together.
It dawned on me that this is a constraint satisfaction problem (CSP); and modeling CSPs is something I've been doing for the last year.
Constraint Satisfaction Problems
CSPs are a family of problems where you are required to find the value to a number of variables given certain constraints to those variables. There are many areas that such problems occur, one such area is packing optimisations.
There are software engineering roles that rely on solving these type of questions; typically these roles will include the term "Formal Methods" under their list of responsibilities.
To solve a CSP problem, we begin by modelling the problem mathematically. There are a few notations that allow us to define the variables and constraints for these kinds of problems, the one I am familiar with is called SMT-language.
Here is a simple example where we wish to find valid values for x and y:
(declare-const x Int)
(declare-const y Int)
(assert (> x 0))
(assert (< y 10))
(assert (= (+ x y) 15))
(check-sat)
(get-model)
You may have noticed that this uses prefix notation, i.e.
(> x 0) which is equivalent to (x > 0) in the familiar
infix notation.
To find valid solutions we need a solver such as z3.
If we provide z3
with the file above it will give us a solution for x and
y that fits the constraint. E.g x = 15 and y = 0. There
may be more than one valid solution. Sometimes there is not
solution and it will return unsat. Short for
unsatisfiable.
Knapsack problems
We can use z3 and smt to model and solve a classic knapsack problem. Given the following products:
- Product A has a size of 3 and value of 4.
- Product B has a size of 5 and a value of 7.
Pack a bag with a capacity of 16. Maximizing the total value of the bag.
(declare-const productA_count Int)
(declare-const productB_count Int)
(declare-const total_value Int)
(assert (>= productA_count 0))
(assert (>= productB_count 0))
; Product A: size=3, value=4
; Product B: size=5, value=7
; Bag capacity: 16
(assert (<= (+ (* 3 productA_count) (* 5 productB_count)) 16))
(assert (= total_value (+ (* 4 productA_count) (* 7 productB_count))))
(maximize total_value)
(check-sat)
(get-model)
Solving this tells us that if we pack two of each product we maximize the total value of the bag; this being 22.
Seating
Getting back into the seating chart. I wrote (vibed) a program that allowed me to draw different connections between each of my guests. These connections account for the different constraints we wanted to map onto the guests. So if A and B are a couple, ensuring they sit next to each other is a constraint.
Here is a complete list of the constraints that were modeled:
- Sit next to each other.
- Sit opposite each other. Or constraint 1.
- Sit diagonally across from each other. Or constraint 2.
- Not next to, not opposite and not diagonal from each other.
- A should be next to B OR C.
After drawing all these constraints between our guests this is how the wedding looks:
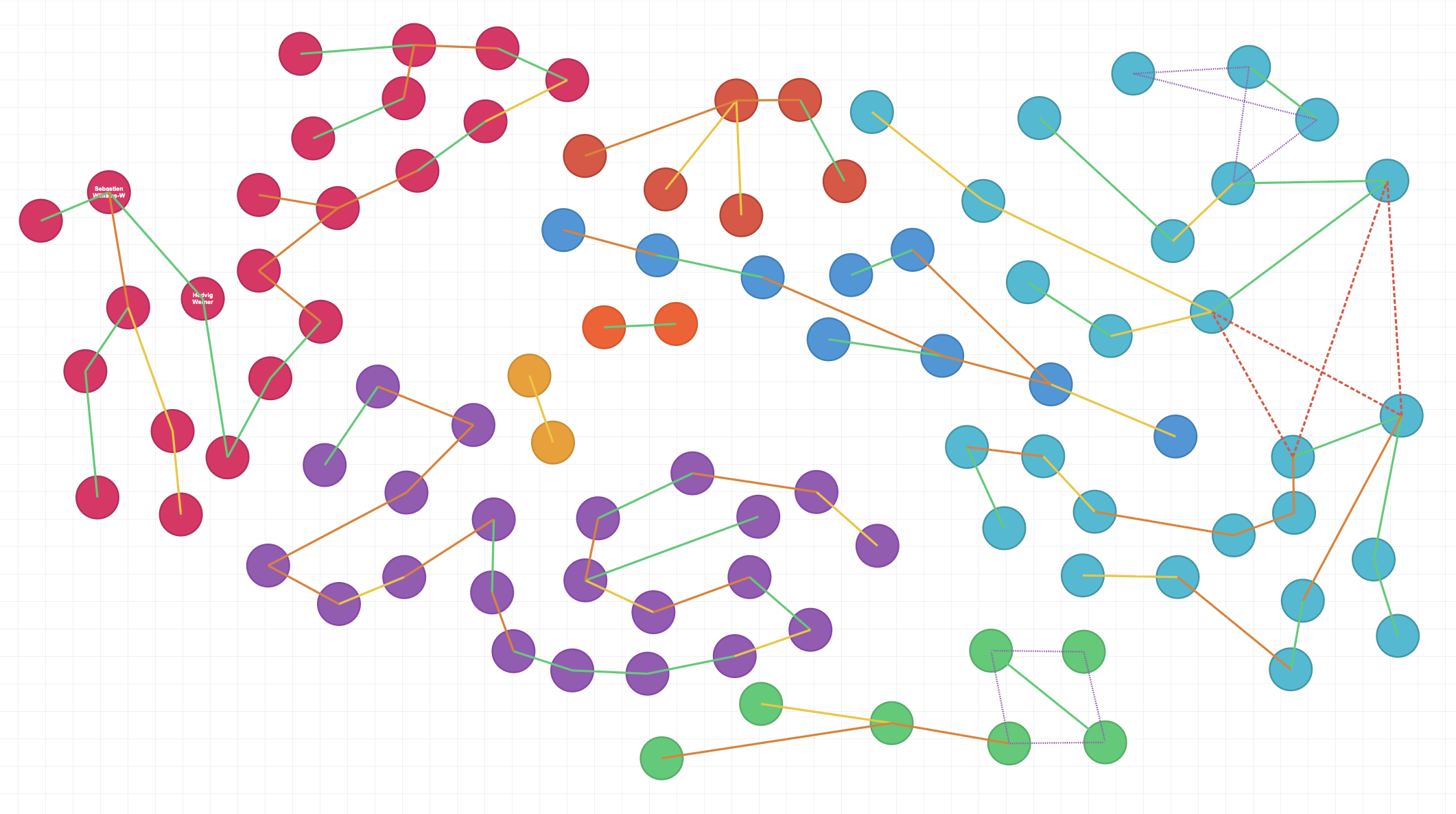
Green is constraint 1, yellow 2, orange 3, dashed red 4 and dashed purple is constraint 5.
We are seating everyone at two large tables. As would have been done in a classic viking longhouse. In order to model the guests at these tables each guest will need a variable for the position, the side and the table.
The groom will have an assigned seat, in the middle of the first table facing inward, towards the guests. As guest number 1 he would have the following variables:
# table_1: int = 0
# pos_1: int = 12
# side_1: bool = true
This would seat me in the middle of the table looking out
across the room. We then define these variables for all 100
guests. We also need to include a constraint that all the
table_{n} variables must be 0 or 1, since there are only
two tables. Additionally the pos_{n} variables have to be
between [0 and 25) since there are only 25 seats on each side
of the tables.
Constraints
Now we model each constraint listed above. The first constraint states that guest A and B must be next to each other. If we take guests 11 and 12 this would look like the following:
(assert (= table_11 table_12))
(assert (= side_11 side_12))
(assert (or (= pos_11 (+ pos_12 1) (= pos_12 (+ pos_11 1)))))
I.e. Same table, same side but their positions are offset by 1 or -1.
The next constraint allows the guest to
not only sit next to someone but as an alternative they can be
opposite each other. To do this we assign the above
constraint to same_side_const and define a new constraint
assign it to opposite_const and in order to satisfy either of
them we say. (assert (or same_side_const opposite_const)).
Here's the definition of opposite_const:
(assert (= table_11 table_12))
(assert (distinct side_11 side_12))
(assert (= pos_11 pos_12))
I.e. Same table, different sides but same position.
For the 3rd constraint we merge constraint 1 and 2 together. B needs to have a different side to A and the position needs to be offset by 1 or -1.
Using the tool above to define the graph constraints I could then export the constraints to be passed into a script that generates the smt file for z3. It then provided a solution that I could import into the same tool to see a visual representation of how it would seat all the guests. You can see that below:
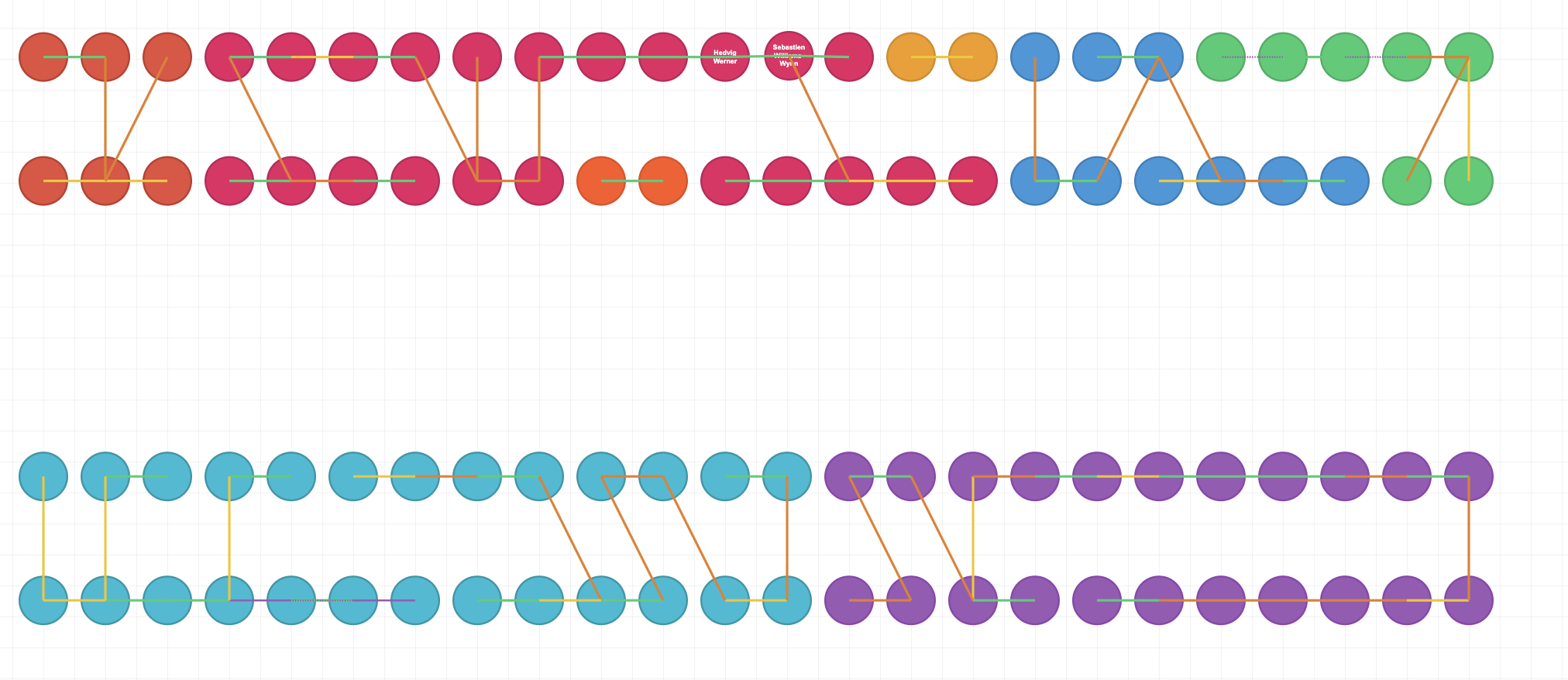
As you'll notice from the colour of each line, all the constraints are satisfied.2
Results
So after 5 hours was this seating chart useful? Not really...
The guests that are on the edge of each of the clusters weren't really people we wanted to sit together. However the arrangement within each cluster was great.
Was this fun? Totally!
I'm not going to do this again, because I'm not going to be married again, but in the event that I have to create a seating chart for 100 people in the future there are certain things that might provide a better outcome.
Perhaps it would be better to rely on more flexible constraints, as an example instead of saying A and B need to be in close vicinity I would instead say A should sit next to at least B, C or D. Giving more flexibility to who A can be sat next to.
After presenting this analysis to my future wife she showed me how she had laid out the tables. You can see this below.
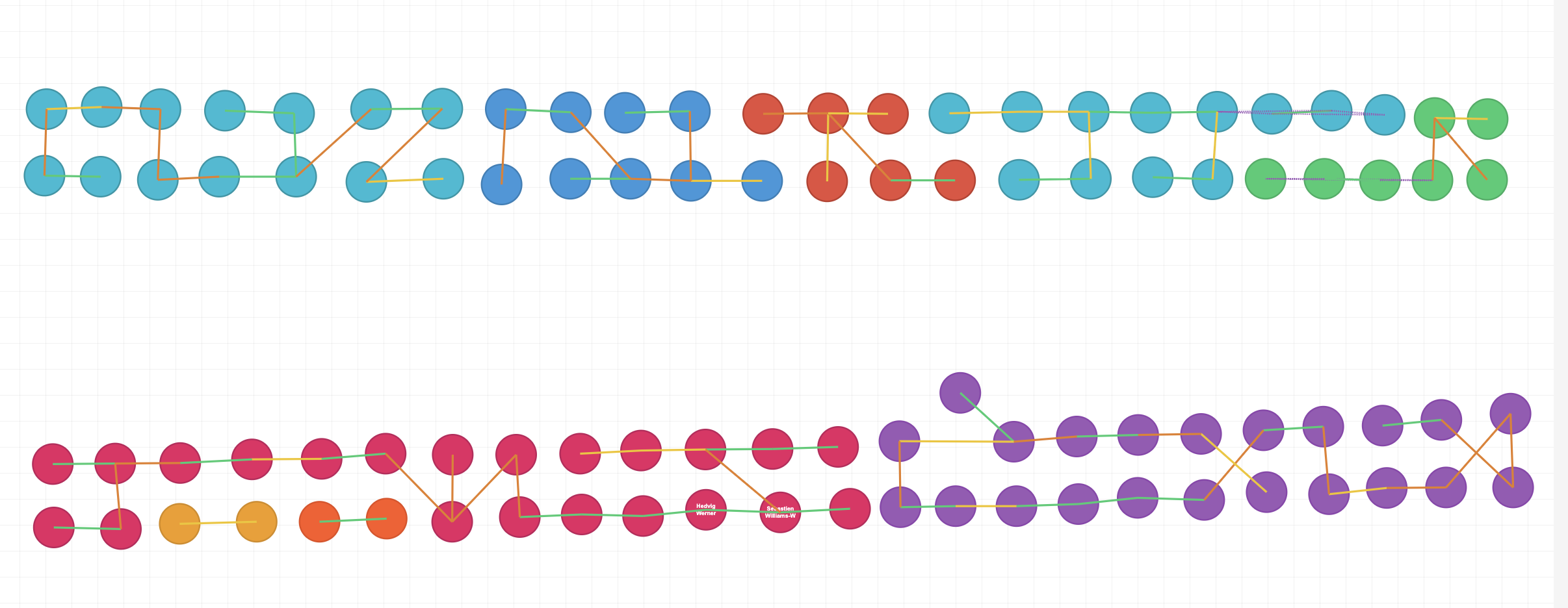
Since the constraints are already linking the guests, I was able to spot some improvements to the chart and get some value from this effort.
There was another improvement to the modelling I could have made when looking at the final chart.
If we wanted A to sit next to C and A was in a couple with B. I had not considered that it was probably fine for B to sit next to C instead of A. If C would get on with A there's a chance they would also get on with their partner B. So I could have relaxed this constraint and had C sit next to either A or B.
Creating a seating chart is not a recurring problem of mine, so sadly there's no need for me to refine this solution further.
Guests forgetting to tell me that they're coming has also caused me to pull some hair out, as with most math, when it attempts to model the real world.
Mon 22 December 2025
Leadership Offloading
How to scale leadership and accelerate business.
Leadership should not stop at getting people to rally around a single cause. We can judge a leader not only on their ability to provide purpose but also on their ability to scale influence.
Cognitive Offloading
Cognitive offloading is the act of using tools and technology in order to reduce the amount of burden placed on our brains. We rely on taking notes and setting reminders so that we don't have to keep consciously telling ourselves or remembering what was said or what needs to be done.
In the same manner this term inspired leadership offloading where we use our influence and actions in order to steer a business or team in the same direction without needing to be in every meeting and every room.
The influence of clarity
Great leaders tend to be clear and concise in how they give others a sense of purpose. Having a clear sense of purpose is the first step in offloading leadership if we provide team with clear expectations and trust them to perform in their role we leave ourselves free to focus on other critical parts of the business.1
Consistency in decision making is equally important when it comes to scaling your impact. It is through consistency that we can start to affect the decisions of others through influence. A measure of this effectiveness can come from how a colleague may get an answer to their issue from framing the question as if they were going to ask you. If they can get answers through the act of framing the question; then you've provided guidance through influence.
Leaders that don't provide clarity or are wildly unpredictable create more work for themselves. If your cohort would be surprised or are not sure how you might respond then you will get more question and increase the burden of needing to be involved in most decision making.
An area that leaders can practice being consistent is how they draw focus to specific tasks and identify distractions that steer us away from achievements. Informing others of the intent of our actions, as well as how and why something aligns with business objectives can inform others of how we are making decisions. Leaders that keep these reasons to themselves are often those that are afraid of their cohort's success and use opaque information to serve their own advantage.
The influence of action
The rumour mill is another surface of influence. Stories and tales about a leader's reaction to certain characters and how they express their expectations can circulate large organisations. Through mimicry this can create cohesion or division depending on the behaviours they target and expressed.
Leaders must be on the look out for opportunities that present concrete examples what the business values. Through their own actions or through promoting the actions of others.
We should not rely on demanding behaviours vocally or use bureaucratic checkboxes to identify talent. If you want people to behave in a certain manner, leaders must be the first to provide the examples of how others can do it.
If new joiners and juniors are not asking enough questions perhaps it is because the leaders themselves are quiet.
The influence of knowledge
It is far better to offload knowledge than to restrict the team's capacity by becoming a bottleneck. Leaders should find all manners and ways of being useful without being present. One such way is by jotting down documentation and notes. Overcoming a challenging task is an experience that should be shared. We must hold the hope that the next person on a similar task can be provided with a smoother course. Instead of facing the problem again from step one.
Additionally this helps us avoid repeating the same mistakes. We don't need to restrict this to technical process knowledge. We can learn from a negative experience from candidates during the hiring phase or how a sensitive topic was raised among the team.
Leaders can encourage TDDs, post-mortem write-ups and even to make rough notes in places that are discoverable. Starting with a few pointers is better than starting from no-where and these all increase the impact one can have across a business.
Those that play the game politically and keep their cards close do so to the company's and their own detriment as this hampers influence and the scale in which you can exert impact.
Even if these notes haven't found an audience, showing the effort and having the intent can inspire others to share information. Sooner or later you will have an environment where colleagues can find context and knowledge far easier than before.
The more context and awareness people have at work. The more valuable they can be. Leading to a higher chance of moving the company from maintenance to growth.
Nudge
Don't only be a consumer of the company's culture, actively contribute to it. A positive culture and leading through example will shift the business into one that shares knowledge and has open collaboration.
It is through the subtle nudges of behaviour and habit that we can compound the impact of our teams and spread influence, all without being in the room.
-
Developing yourself can also be considered critical. ↩