Tue 21 April 2026
Probabilistic Data Structures
Keeping track of a constant set of items is fairly straight forward, however when the number of items start to grow larger than the capacity of a single machine things get expensive. There's a way around this and it's to rely on approximations instead of concrete numbers. There are two probabilistic data structures I'd like to cover in this post; Bloom Filters and Count-Min Sketch.
Generally these are applied when space is a constraint and you need predictable and consistent size. If you're counting or caching at scale there might be a chance that your database is relying on probability instead of certainty.
Hash Tables
A fundamental data structure in computer science is the hash table, useful in caching and counting, as well as representing objects in software.
A large hash table is often useful when you need a key value store such as one that would map user ID to a profile picture so that every request for a profile picture is speedy since hash tables operate in 0(1) for look ups.
This is done by having a number of buckets and a function that consistently converts a key to the index of a bucket. This is called the hash function. A cache or a key value store only requires computing the hash to locate the data.
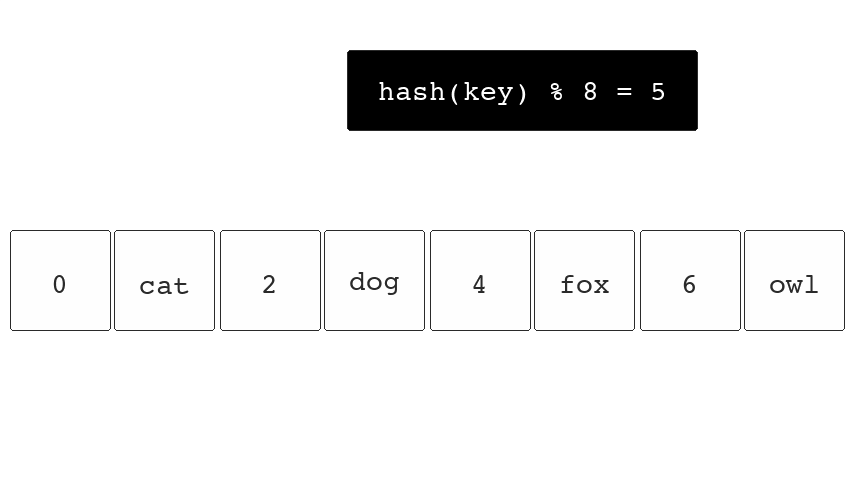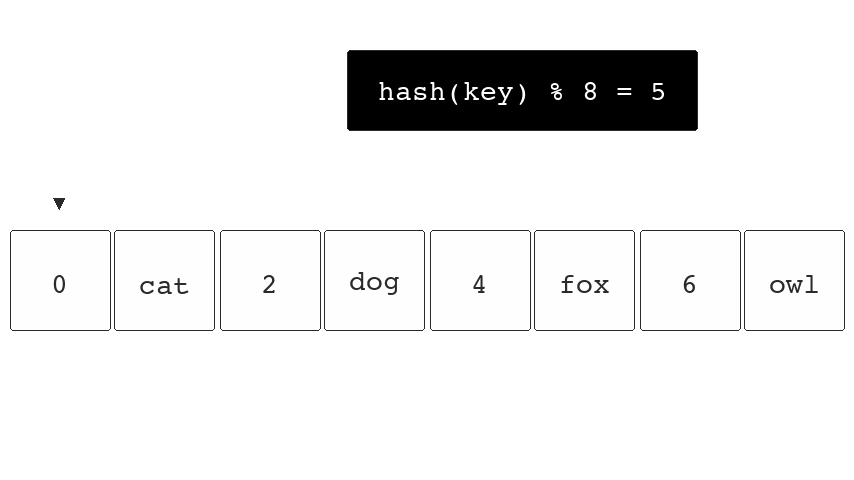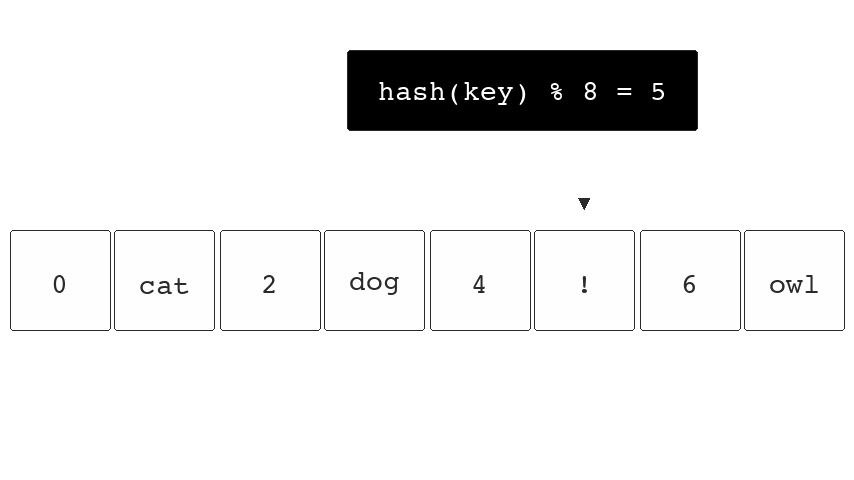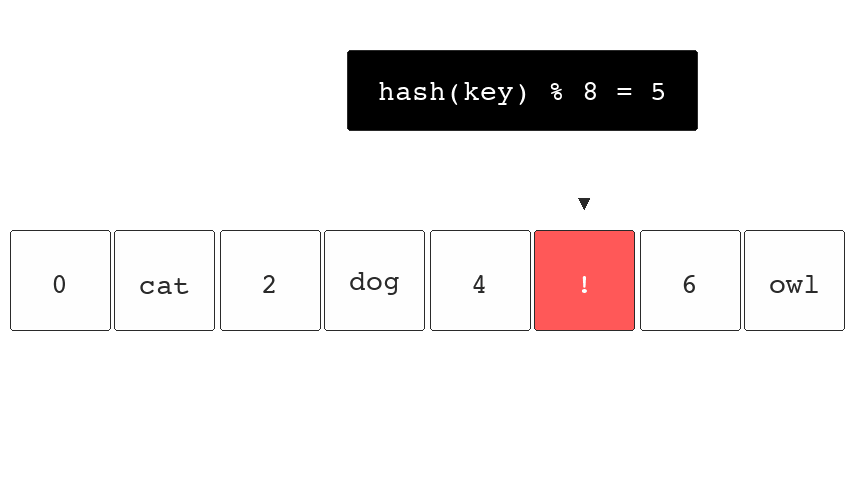
If we were to hash the key "fox" (hash("fox")) and the
resulting output was 5 we would know our data is in bucket
5.
Hash functions won't compute unique hashes and occasionally
they can collide with existing keys stored in the hash
table. So both hash("fox") and hash("cat") might end up
pointing to bucket 5. They can reduce the chance of this
happening by increasing the number of buckets. Having 10
keys and 1 million buckets means the chance of collision
becomes extremely small.
In practice hash tables store linked lists in the bucket locations and when a collision occurs they iterate through the list until it finds the key. When storing a new key it appends to the end of the list if it's not there already. Redis uses this technique in addition to resizing the number of buckets dynamically in-order-to keep the length of these lists to a minimum.
We can use hash tables to determine if we've seen something before, by storing keys as we see them, if the key exists in the hash table we know that this isn't the first time we've seen the item.
Bloom Filters
When we start dealing with data streams or billions of users, storing everything in memory can be expensive. Instead we can reduce the total memory consumed by using a probabilistic data structure; the bloom filter.
Bloom filters rely on approximate set inclusion. So instead of yes this item is in the set or no it isn't; we get the following outcome:
- This item is not in the set.
- This item might be in the set.
This is done by having a consistent number of buckets and using more than one hash function. As you can see in the illustration below, the key is hashed three times and each resultant bucket is set to 1.

When items are queried we will know for sure that we haven't seen it before if any of the buckets return a 0. However if all the buckets result in a collision then we know that we might have seen it before.
Both the number of buckets and hashes can be configured which allows us to trade more space for a reduction in the probability that we return false negatives. (We might have seen it, when we haven't).
The bloom filter is applied in situations where space is limited and keeping track of every element isn't an option. If we wish to avoid making expensive queries for data that doesn't exist; a bloom filter can help us reduce the number of expensive queries.
Browsers have used bloom filters in the past by providing a preset filter of malicious URLs. When we visit a URL and it's not included in the filter we can proceed however if it might be in the filter we can query a server to help determine if it's safe or not. We avoid this query on the majority of URLs as most URLs are safe.
Count-Min Sketch
The last probabilistic data structure I'd like to cover is the Count-Min Sketch, like a bloom filter it has multiple hash functions, unlike the bloom filter it tracks the number of times a key lands in a bucket.
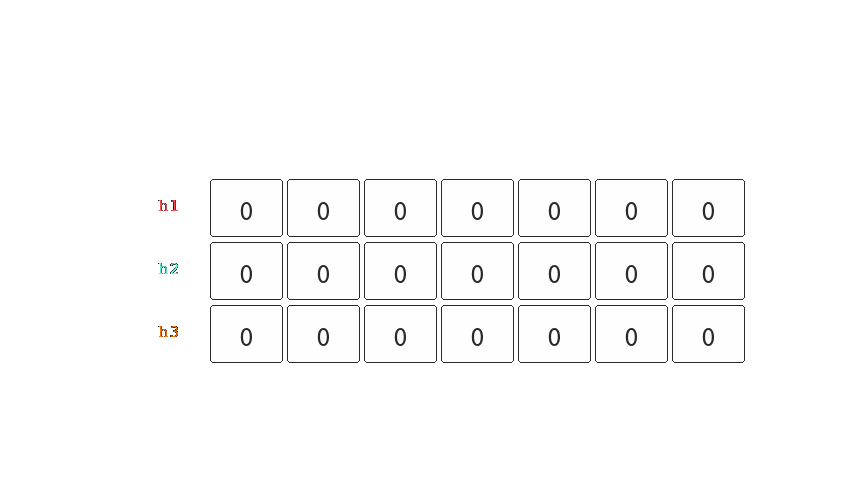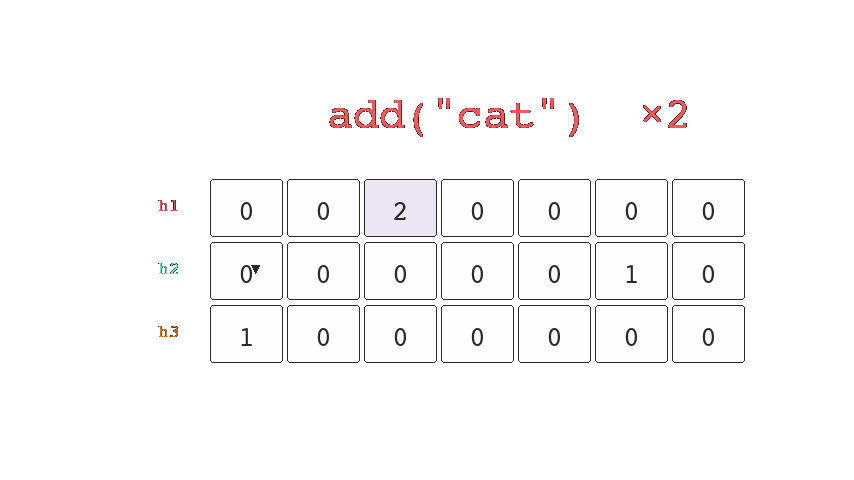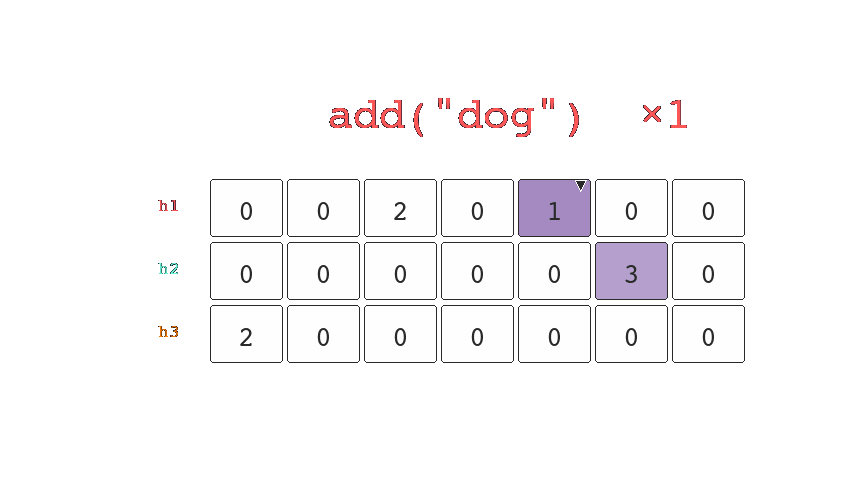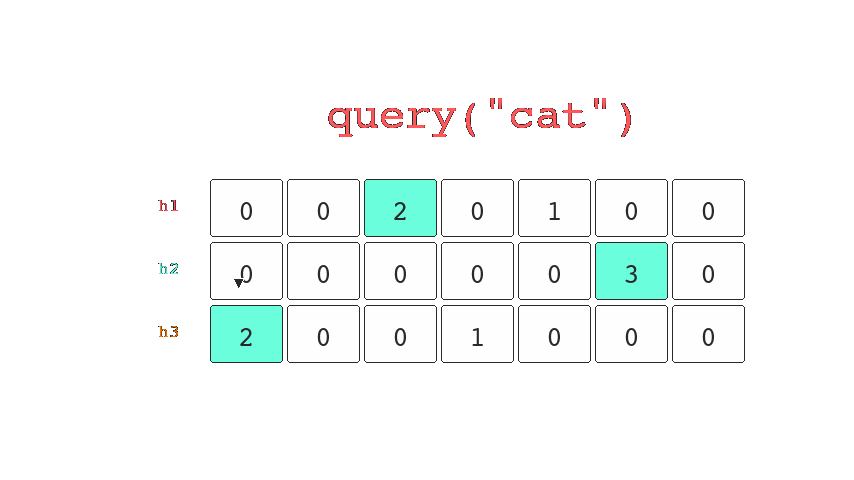
When queried it hashes the key and returns the minimum from the counts stored in the corresponding buckets. This allows us to determine an upper bound estimate for the number of times we've seen a key.
Count-Min Sketch is useful in large scale data processing,
for example if we are interested in tracking the top-k
searches we can do this normally by using a heap. If we have
size restrictions and need to use constant space instead of
O(n) space we can put the sketch in front of the heap.
Heap inserts are done in log(n) time which we can avoid
doing if we know the item shouldn't be in the heap. Items
that appear infrequently are then discarded before even
making it to the heap. We do this by querying the sketch for
an upper bound of the new item, for example 3, and if the kth
item in our heap has 12 appearances then we can avoid adding
the new item to the heap.
I have found it interesting that at scale we can use probability to optimise our systems but it also requires an understanding of how the data is distributed. These data structures work well on long tail distributions but when all items are as frequent as each other these become less useful. It would be interesting to discover how systems can map to different distributions of data and how these structures are set up to solve the given problems.